
The Assumption Everyone Gets Wrong
Walk into any AI infrastructure meetup and ask people what OpenAI runs in production. You'll hear three answers, repeatedly:
- "Probably vLLM at scale."
- "SGLang with custom modifications."
- "Some fork of TensorRT-LLM."
All three are reasonable guesses. vLLM and SGLang are genuinely excellent engines. PagedAttention changed how the entire industry thinks about KV memory management. Prefix caching in SGLang is legitimately impressive. These are the tools that show up everywhere when you serve open-weight models.
And all three guesses are most likely incomplete.
The better explanation is that OpenAI is not running a stock open-source inference engine in the production hot path. The public signals point toward a custom serving stack: one built around their models, latency targets, compliance requirements, billing system, and enterprise SLAs.
So the useful question is not "which open-source runtime do they use?" The useful question is: what would OpenAI's inference architecture need to look like to support the product behavior visible from the outside?
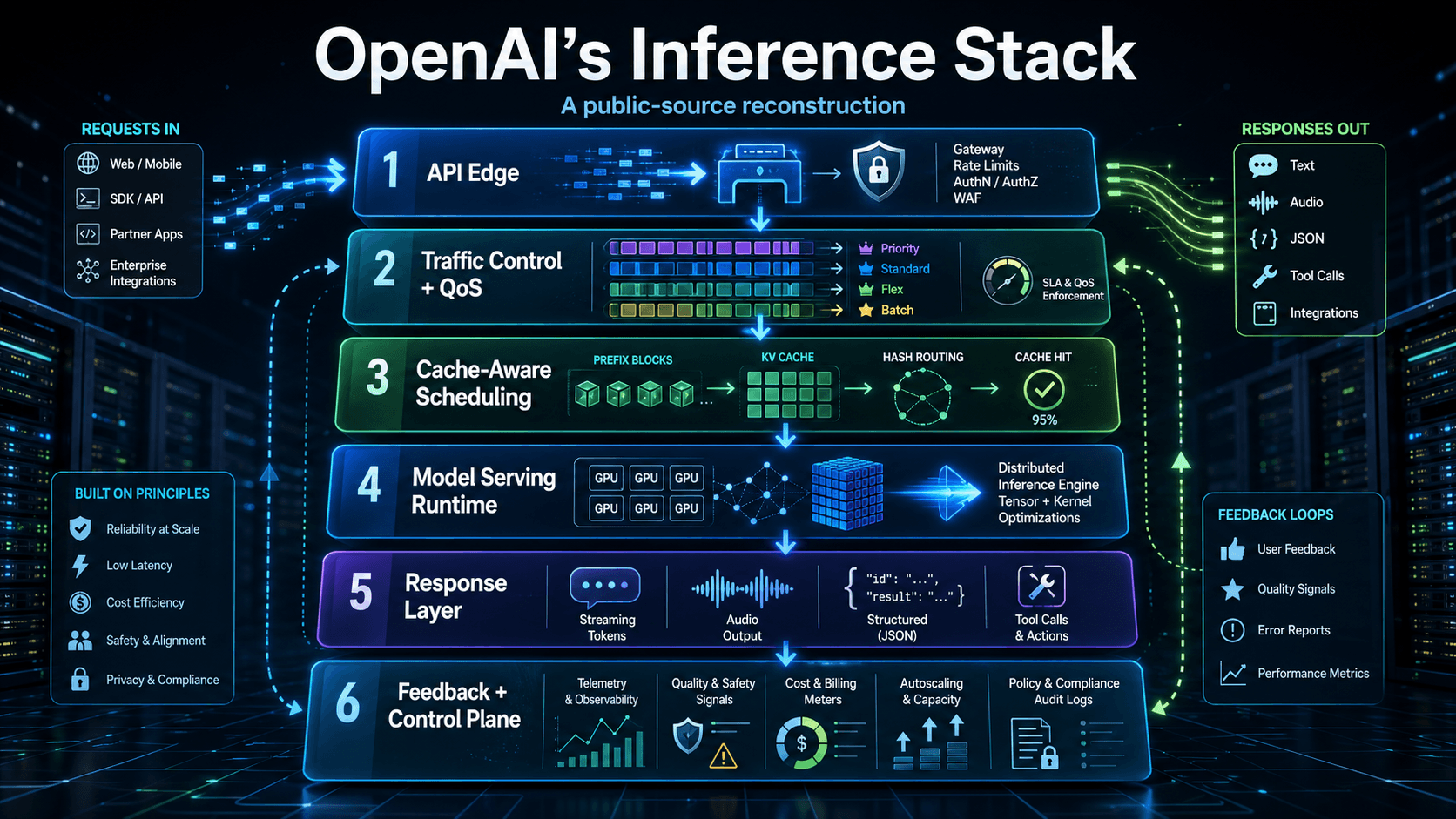
The most probable answer is a layered system: API edge, traffic control, cache-aware scheduling, distributed GPU runtime, response streaming, and a feedback control plane.
The Big Picture
The most likely architecture has six layers:
- API Edge
- Traffic Control and QoS
- Cache-Aware Scheduling
- Model Serving Runtime
- Response Layer
- Feedback and Control Plane
The important part is that this is not just an inference engine. It is probably an inference engine plus a compliance layer plus a billing system plus a scheduler with real QoS enforcement, all moving together under one team's control. That integration is the point.
The Core Claim: Custom Stack, Not Commodity Runtime
The production setup most likely is not a plain vLLM, SGLang, or TensorRT-LLM deployment. OpenAI's public hiring language points toward deeper infrastructure ownership:
- "Our inference stack", not "our vLLM deployment."
- Optimizing Azure VM fleets at scale.
- Writing custom CUDA and Triton kernels.
- Low-precision compiler work such as FP8 and INT4.
- Collective communication tuning across hundreds of GPUs.
- Hardware/software co-design down to rack and datacenter networking.
That does not look like the profile of a team only operating a stock open-source engine. It looks like the profile of a team building and tuning core infrastructure.
One important nuance: an OpenAI AMD GPU enablement role explicitly mentions integrating their internal serving infrastructure with "vLLM, Triton" for hardware bring-up. So the picture is probably custom core, selective external integration, not "they never touch open-source tooling." When new hardware arrives, teams use what works to validate the silicon. But the main production path appears to be owned internally.
Layer 1: API Edge
This layer handles TLS termination, authentication, organization and project lookup, rate limiting, and request normalization. Standard infrastructure, but it sets up everything downstream.
The interesting bit is that the API Edge feeds directly into a tier classification system that determines which compute lane your request runs on. That brings us to the next layer.
Layer 2: Traffic Control and QoS
OpenAI publicly sells five distinct execution lanes: Priority, Standard, Flex, Batch, and Background. This is not just pricing differentiation. It is literal queue separation over shared compute.
Here's how each lane behaves:
- Priority: Premium pay-as-you-go, faster and more consistent latency, billed at a higher per-token rate. Designed for SLA-bound flows.
- Standard: The default pay-as-you-go service. Best-effort but generally fast.
- Flex: Roughly 50% cheaper than Standard, slower, may queue or return 429s under load. Best for async work that can tolerate latency.
- Batch: Asynchronous processing with a 24-hour SLA, also 50% cheaper than synchronous calls. Separate quota pool from synchronous RPM/TPM.
- Background: Decouples client connections from long-running reasoning jobs entirely.
Then there's Scale Tier, the enterprise commitment plan: you purchase reserved token capacity for at least 30 days, and OpenAI guarantees a 99.9% uptime SLA and predictable latency. This is where production-critical SaaS lives.
The product implication is real. You do not sell a 99.9% uptime SLA on top of a shared inference fleet without a scheduler that can actually enforce differentiated service levels. The QoS layer has to be a first-class component of the stack.
Layer 3: Cache-Aware Scheduling
This is where the architecture becomes more interesting, and it is the layer with the most public documentation.
How prompt caching works
OpenAI automatically enables prompt caching for prompts of 1024 tokens or longer. Cache hits occur in 128-token increments beyond that. The mechanics, taken from OpenAI's own documentation:
- Incoming request arrives at the scheduler.
- The system computes a hash of the initial prefix of the prompt, typically the first roughly 256 tokens.
- The request is routed to a machine that has previously processed that prefix.
- If the prefix is in cache on that machine, the model skips recomputing it and starts generating from the cached state.
This produces dramatic latency savings. OpenAI's own data shows time-to-first-token reductions of up to 80% on long prompts, and input token costs drop by up to 90% on cached portions.
The rule is crisp: cache hits require an exact prefix match. Even one different token at position zero, such as a leading space or a different greeting, means the prefix has to be recomputed. This is why the advice is to put static content, such as system instructions, tool definitions, and few-shot examples, at the start of your prompt, and dynamic content, such as the user's actual question, at the end.
Hotspot Protection
Here is the production-grade detail that matters. If the same prefix-plus-user combination generates more than approximately 15 requests per minute, traffic overflows to additional machines and cache effectiveness degrades. That is hotspot protection: preventing any single popular prefix from concentrating too much load on one machine while the rest of the fleet sits idle.
Extended Caching and Privacy
For models like GPT-5.5, OpenAI offers Extended Prompt Cache Retention, keeping prefixes warm for up to 24 hours. The implementation detail matters here:
Extended Prompt Caching works by offloading the key/value tensors to GPU-local storage when memory is full. Only the key/value tensors may be persisted in local storage; the original customer content, such as prompt text, is only retained in memory.
This matters because the system is not caching the prompt text on disk. It is caching the intermediate model state: the KV tensors from the attention layers. The original text stays in memory.
And critically: prompt caches are not shared between organizations. Each organization gets its own isolated cache space. This is the kind of multi-tenancy guarantee that does not exist out of the box in any open-source serving engine.
Layer 4: Model Serving Runtime
This is where the actual model execution happens. OpenAI does not disclose the specifics, but job postings, product behavior, and Azure's documented infrastructure point in the same direction.
Prefill and decode separation
OpenAI does not explicitly say they separate prefill from decode, but the product behavior strongly suggests it, and it is the central insight of recent inference research. Papers like DistServe and Splitwise made the case rigorous.
Here's why the separation matters:
- Prefill processes the entire prompt to build the initial KV cache. It is compute-heavy, parallelizable, and benefits from large batches.
- Decode generates tokens one at a time, autoregressively. It is memory-bandwidth-bound, latency-sensitive, and benefits from small batches with high concurrency.
Running these two phases on the same GPU pool means one of them is always the bottleneck. Separate them, and you can independently scale each. OpenAI's pricing explicitly distinguishes prompt token costs from output token costs, which lines up with this separation.
vLLM has shipped disaggregated prefill/decode in its V1 engine as a configurable option. So this is not proprietary magic. But in OpenAI's case, it is woven into the production scheduler rather than offered as an opt-in feature.
Distributed GPU Runtime
OpenAI's serving runtime is sharded across multiple GPUs using a combination of techniques:
- Tensor parallelism (TP): Splits individual matrix operations across GPUs.
- Pipeline parallelism (PP): Splits the model layers across stages.
- Expert parallelism (EP): Used for MoE models, distributing experts across GPUs.
OpenAI job postings explicitly call out NCCL/RCCL collective communication libraries and serving 10B+ parameter models across many-GPU nodes.
The hardware underneath is Azure's ND H100 v5 series:
- 8 NVIDIA H100 GPUs per node
- NVLink 4.0 for full intra-node bandwidth
- 400 Gb/s InfiniBand per GPU for scale-out
- Purpose-built for sharded inference
Kernel and Compiler Layer
Custom kernels for fused attention, GEMM operations, and sampling. Low-precision compiler work for FP8 and below. This is where the team's hardware/software co-design shows up, and it is the layer where the difference between "running an open-source engine" and "owning the stack" becomes most visible.
Kernel-level optimization is hard, expensive, and only justifies itself at the kind of scale where every percentage point of throughput translates to millions of dollars.
Layer 5: Response Layer
This handles output sampling, structured outputs such as JSON mode and tool calls, post-processing for safety and moderation, and streaming transport back to the client.
OpenAI supports three transport protocols:
- Server-Sent Events (SSE): The default streaming format for the Chat Completions and Responses APIs.
- WebSocket: Used for the Realtime API.
- Realtime audio streaming: Sub-second multimodal audio for voice mode.
The GPT-4o Proof Point
One useful signal that OpenAI's serving stack is purpose-built for its models is how dramatically GPT-4o changed voice latency.
Before GPT-4o, ChatGPT voice mode was a three-model pipeline:
- Speech-to-text converts audio to text.
- A text LLM generates a response.
- Text-to-speech converts the response back to audio.
The latency numbers OpenAI published:
- GPT-3.5 voice mode: 2.8 seconds average response time
- GPT-4 voice mode: 5.4 seconds average response time
When GPT-4o launched, all three models collapsed into a single end-to-end omni model. The new numbers:
- GPT-4o voice mode: 320 milliseconds average, 232 ms floor
That's a 9x speedup over GPT-3.5 and a 17x speedup over GPT-4. And it gets you to 232 ms, which is right at the edge of natural human conversational latency, around 150-200 ms.
That kind of latency is unlikely to come from a generic "serve a HuggingFace checkpoint" setup. Unified multimodal tokenization, low-latency audio paths, and realtime tool integration have to be built around the model. The serving stack and the model architecture likely co-evolve.
Throughput Across Models
A few things stand out when comparing observed tokens-per-second across OpenAI models in production:
- GPT-3.5 Turbo delivers roughly 60-77 tokens/sec, fast because it is a smaller model.
- GPT-4 Turbo sits at 32-41 tokens/sec, where the size penalty is real.
- GPT-4o ranges from about 36 to 80 tokens/sec, with a wide variance.
That GPT-4o variance is worth noting. It suggests the serving stack may dynamically adjust based on load and routing decisions. Different requests can land on different paths, and throughput reflects it.
The takeaway: OpenAI is not necessarily winning on raw output tokens-per-second. Specialized small models can top raw speed charts. The more important advantage is the combination of intelligence, latency, multimodality, and enterprise compliance delivered through a single unified API. Raw speed is one variable in a much larger optimization problem.
Layer 6: Feedback and Control Plane
The final layer closes the loop:
- Telemetry pipeline: Captures latency, token counts, and cache hit rates per request.
- Billing and usage metering: Per-organization accounting for input tokens, output tokens, cached tokens, and Batch API discounts.
- Autoscaling and capacity management: Fleet health monitoring, placement decisions, and capacity planning.
This control plane is likely what allows OpenAI to commit to enterprise SLAs in the first place. You cannot honor a 99.9% uptime guarantee without continuous capacity planning and automated remediation. Every signal from the serving fleet has to feed back into placement and scaling decisions.
How This Compares to vLLM and SGLang
vLLM and SGLang are excellent. Let's be specific about what each has shipped.
vLLM:
- PagedAttention for KV memory management.
- Continuous batching at iteration granularity.
- Prefix caching, chunked prefill, speculative decoding.
- Multi-LoRA batching and FP8 quantization.
- Disaggregated prefill/decode in the V1 engine.
- 200+ supported model architectures from HuggingFace.
SGLang:
- RadixAttention for tree-structured prefix caching.
- Strong speedups on structured workloads.
- Strong support for structured outputs and constrained decoding.
These are world-class inference engines. But here's the structural difference. Engines optimize the inner loop: how to run a model fast. They do not ship with:
- Zero Data Retention (ZDR) compliance modes.
- Organization-scoped cache isolation by default.
- Differentiated QoS lanes as a built-in product.
- Regional inference pinning for data residency.
- Enterprise key management and audit trails.
- Scale Tier-grade SLO commitments.
OpenAI's serving stack is probably not just a faster engine. It is likely an engine plus a compliance layer plus a billing system plus a multi-tenant scheduler with real QoS enforcement, all moving together under one team's control. That integration is what customers pay for, and it is what is hard to replicate.
What's Still Unknown
It is worth being honest about the limits of public reconstruction. Things OpenAI has not disclosed and which can only be guessed at:
- The exact batch scheduler algorithm. Is it iteration-level continuous batching like vLLM, or something more sophisticated?
- Whether their MoE models use expert parallelism, and if so, what the routing strategy looks like.
- How deep ONNX or TensorRT integration goes.
- The precise sharding topology for different model sizes.
- How they handle cross-region failover for Scale Tier customers.
- The internal structure of the realtime audio pipeline.
The honest summary: the broad shape is reasonably inferable, but the exact implementation details are not public.
Why This Matters for Anyone Building Inference Infrastructure
If you're designing a serving platform today, the architectural questions OpenAI's stack raises are the right ones to be asking:
- Is your scheduling cache-locality-aware, or request-agnostic? Routing to the machine that already has your prefix in cache is a huge latency win on long prompts. Hash-based prefix routing is not optional at scale.
- Are you separating prefill and decode compute? They have different performance profiles: compute-bound versus memory-bandwidth-bound. Running them on the same pool means one is always the bottleneck.
- Do your QoS controls actually enforce differentiated latency, or do they just sort queues? Real QoS means reserving capacity, not just prioritizing within shared capacity.
- Is your compliance layer integrated into the serving path, or bolted on after? ZDR, org isolation, and regional pinning are much easier to design in from the start than to retrofit.
- Where does your stack stop being commodity and start being yours? OpenAI's answer is: the kernel layer down. Yours might be different, but the question deserves an explicit answer.
The Real Takeaway
OpenAI did not invent most of the ideas in their stack:
- Orca invented continuous batching.
- DistServe and Splitwise made the prefill/decode separation case rigorous.
- vLLM showed you could manage KV memory at page granularity.
- MLPerf benchmarks pushed the entire industry on kernel-level optimization.
What OpenAI appears to have done is productize these ideas at frontier model scale, with enterprise compliance and real SLOs, behind a unified API. That gap, between "the techniques exist in research papers" and "the techniques run a multi-billion-dollar production service with production reliability," is where the interesting engineering still lives.
The next wave of frontier inference systems will be defined less by who has the cleverest kernel and more by who can compose all of these layers: scheduling, caching, QoS, compliance, billing, and telemetry into a coherent system that holds up under load.
Public Signals Used
This is not an official OpenAI architecture diagram. It is a likely technical reconstruction based on public product behavior and public infrastructure signals:
- OpenAI's Prompt Caching documentation and Prompt Caching 101 cookbook.
- OpenAI's Scale Tier and Priority Processing announcement pages.
- OpenAI's "Hello GPT-4o" launch post.
- OpenAI's pricing page and Batch API documentation.
- Azure ND H100 v5 hardware specifications.
- OpenAI engineering job postings for inference, kernels, and AMD enablement.
- vLLM project documentation and the PagedAttention paper.
- SGLang documentation and benchmarks.
- DistServe and Splitwise papers on prefill/decode separation.
The exact internals are not public. The point is to understand the most probable shape of the system from the outside: scheduling, caching, QoS, compliance, billing, telemetry, and GPU execution working as one coordinated stack.
