Most engineering advice tells us to keep databases simple.
Do not create too many tables. Do not abuse PostgreSQL. Do not use a relational database as a cache. Do not do weird things in production.
Then Zerodha came along and showed a system that creates around 7 million PostgreSQL tables in a day.
At first, this sounds like a database horror story.
But it was not a mistake. It was not a junior engineer accidentally generating tables in a loop. It was an intentional reporting architecture used to protect large financial databases from unpredictable user traffic.
The important detail is this:
Zerodha was not creating 7 million tables in its main trading database.
These were temporary result tables created in a separate PostgreSQL results database used by an internal middleware called DungBeetle.
That one detail changes the whole story.
This is not a story about blindly abusing Postgres.
It is a story about workload isolation, async processing, controlled database pressure, and using the shape of your data to choose the simplest possible system.
The Real Problem Was Not How To Run SQL
Zerodha has large financial databases that store trades, ledgers, P&L reports, and other transactional data. Their public engineering material mentions hundreds of billions of rows and around 20 TB of data across sharded PostgreSQL nodes.
Now think about the reporting workload on top of that.
A user opens Console and asks for a report.
Maybe it is a simple trade report. Maybe it is a P&L report. Maybe it is a tax report. Maybe it needs data from multiple tables. Maybe it needs data from multiple databases. Maybe it finishes in milliseconds. Maybe it takes many seconds.
The difficult part is that the system cannot predict this perfectly.
On normal days, traffic may be manageable. But on volatile market days or tax season, thousands or millions of users may request reports around the same time.
If every user request directly hits the large source databases, the database is no longer only serving business-critical workloads. It is also handling unpredictable reporting spikes.
That is dangerous.
A report is important, but it should not be allowed to overload the main database.
The core problem was not SQL.
The core problem was unbounded user demand hitting bounded database capacity.
Why Synchronous Reporting Breaks At Scale
The naive way to build reporting is simple.
User clicks download report. The app sends a query to the database. The database computes the result. The app waits. The user waits. The response comes back.
This is fine for small systems.
But at scale, synchronous reporting creates pressure at multiple layers.
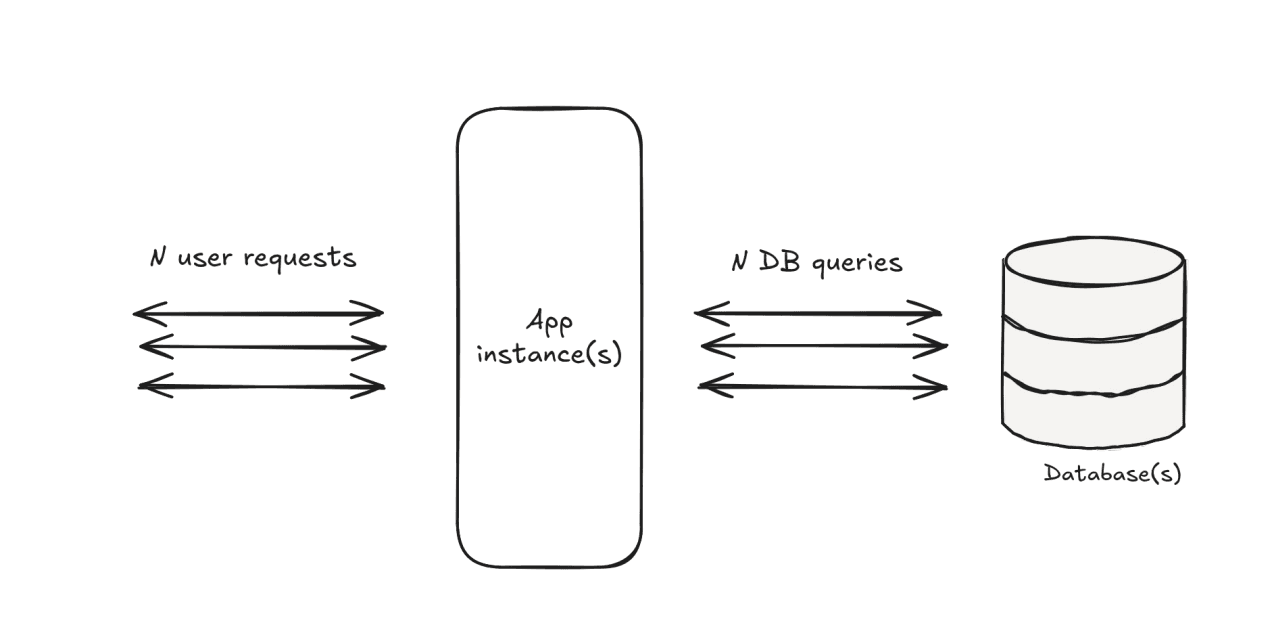
The app keeps HTTP connections open while waiting. The app keeps database connections open while queries run. The database has to execute many queries at the same time. Some queries are small, but some are very heavy. The slow queries hold resources for longer. The system starts queueing indirectly, but in the worst possible place: inside app servers and database connections.
That is the problem.
If queueing is going to happen anyway, it should happen explicitly in a system designed for queueing.
Not accidentally inside the database. Not accidentally inside the app connection pool. Not accidentally because users are stuck waiting on open requests.
This is the first big lesson from DungBeetle:
When a workload is unpredictable and expensive, do not let users directly control database concurrency. Put a controlled queue in between.
The naive model: every user report directly adds pressure to the database.
The Async Reporting Idea
The idea behind DungBeetle is simple.
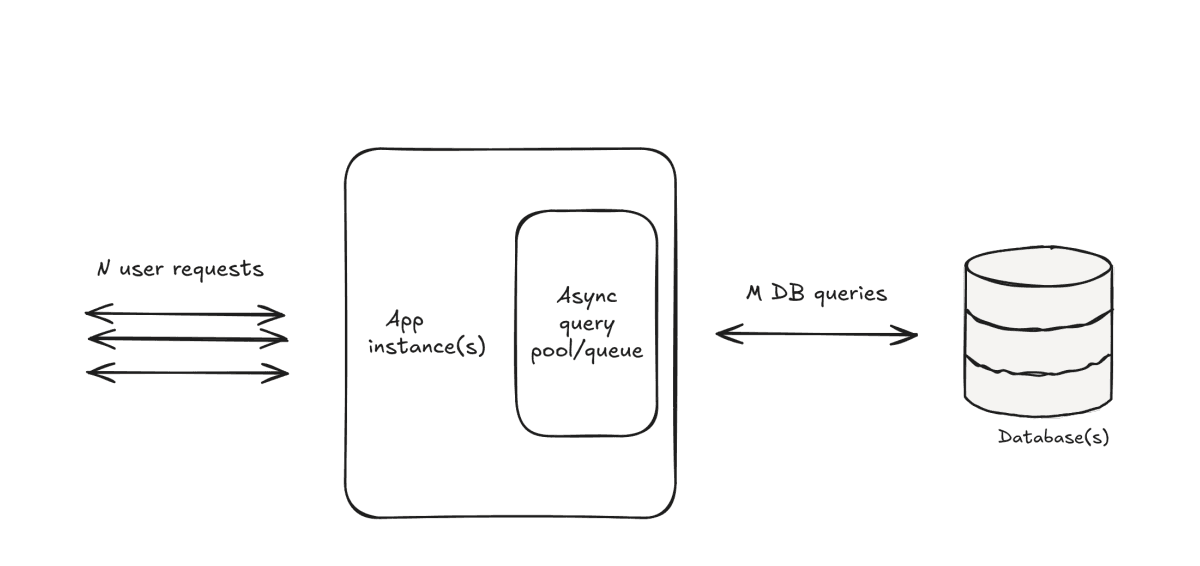
Instead of every app implementing its own report generation logic, Zerodha built an independent middleware for SQL reporting.
A user asks for a report. The app creates a reporting job. DungBeetle queues the job. Workers execute SQL against source databases in a controlled way. When the result is ready, it is written into a separate results database. The app reads the completed result later.
This converts reporting from a synchronous workload into an asynchronous one.
Instead of:
Run this query right now because the user is waiting.
The system becomes:
Accept the request, queue it, run it when capacity is available, and let the user fetch the result when it is ready.
This is not a new idea. Many banks and financial systems do this when they say:
Your statement is being generated. Please come back later.
The interesting part is not async reporting itself.
The interesting part is what Zerodha chose as the result store.
They used PostgreSQL.
Again.
DungBeetle turns unbounded user requests into controlled database query execution.
Why PostgreSQL As A Result Cache Makes Sense
The obvious question is:
Why use PostgreSQL as a cache?
Why not Redis? Why not object storage? Why not a big JSON blob? Why not a single shared results table?
The answer is hidden in the shape of the data.
Reports are tabular.
A trading report is rows and columns. A ledger report is rows and columns. A P&L report is rows and columns. A tax report is rows and columns.
Users do not just want to download raw data. They want to filter it, sort it, paginate it, and view it in a UI.
If the result is stored as JSON, the application has to rebuild filtering and sorting logic.
If the result is stored in Redis, Redis gives fast lookup, but not the same relational query experience.
If the result is stored in object storage, it may be cheap, but interactive filtering and sorting become harder.
But if the result is stored in PostgreSQL, the app can continue treating the result like a table.
That means sorting, filtering, pagination, and SQL-style access are already available.
This is why the idea is clever.
PostgreSQL was not being used as a generic cache.
It was being used as a temporary SQL-readable result store.
That is very different.
Why One Table Per Report Job?
This is the part that makes the story viral.
Every completed job gets its own result table.
That sounds absurd if you think of tables as long-lived schema objects.
But in this case, a table is just a temporary container for one report result.
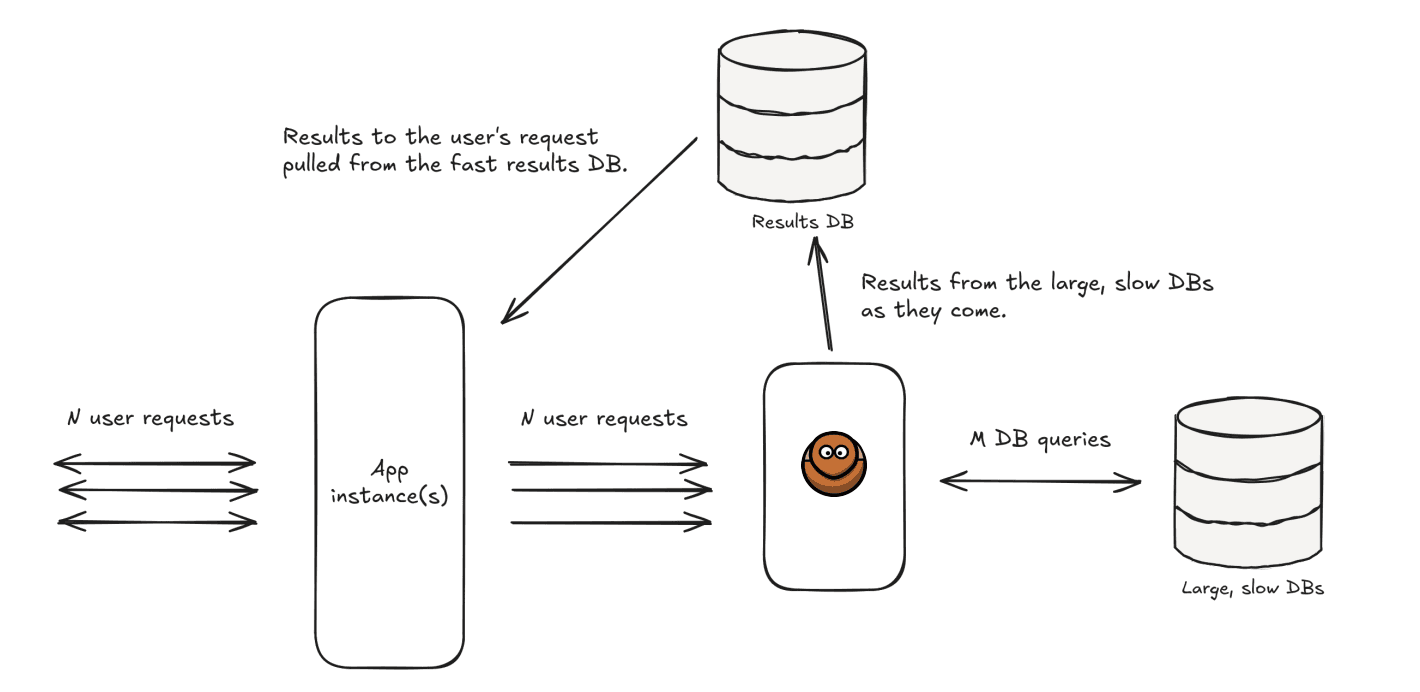
A user asks for a report. The report job runs. The result rows come back. DungBeetle creates a table for that job and writes the rows into it.
The application can then read the table directly.
This avoids mixing many unrelated report results into one giant table. It avoids complicated result ownership logic. It avoids having to design one universal schema for every possible report. It allows arbitrary report columns and types. It keeps each result isolated.
Each job result becomes its own disposable mini-table.
That is the mindset shift.
These tables are not part of the product's permanent data model.
They are closer to temporary files.
Except the "file" is a PostgreSQL table, so the application gets SQL behavior for free.
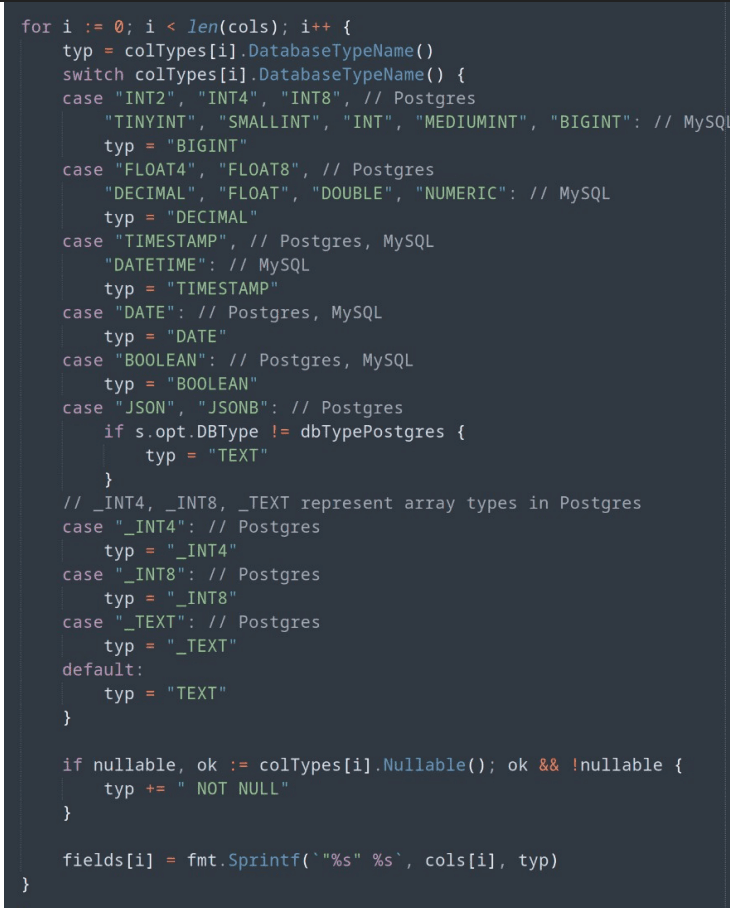
The implementation detail also matches the architecture: DungBeetle has to map source database column types into result-table column types so arbitrary reports can still be queried as relational tables.
Why This Did Not Destroy PostgreSQL
The natural fear is:
Can PostgreSQL even handle millions of tables?
Zerodha's DungBeetle slides show that on a random day, the results database had around 7 million tables, 1 TB of disk usage, and around 60 GB of metadata.
That is not normal database usage.
But it worked because the system was designed around a very specific lifecycle.
The result tables are short-lived. They are not kept forever. The results database is wiped every night. It runs on a separate machine. It does not endanger the main financial databases. It exists to serve report results for a limited period.
This is why context matters.
"7 million tables in a main OLTP database" would be terrifying.
"7 million temporary result tables in a disposable reporting cache database" is still unusual, but much more understandable.
The design works because the blast radius is controlled.
The Nightly Wipe Is Part Of The Design
The nightly wipe is not a cleanup hack added later.
It is part of the architecture's logic.
The results database stores temporary report outputs. These outputs are not the source of truth. The source of truth remains in the original databases.
So Zerodha can wipe the results database every night and start fresh.
This is powerful because it avoids one of the biggest problems with cache systems: long-term garbage collection.
Instead of slowly deleting millions of old rows or managing complicated TTL logic, the entire result store can be reset.
This is similar to treating the results database as a disposable scratch space.
That makes the system operationally simpler.
The data is important while the user needs the report. But it is not permanent business data.
Once you understand that, the design becomes less strange.
Why Not Just Add Read Replicas?
Read replicas are useful, but they do not fully solve this problem.
A replica still has finite capacity.
If report traffic is unpredictable, you can keep adding replicas, but that becomes expensive and operationally messy.
Also, reports are not uniform. Some queries are light. Some are extremely heavy. Some may touch large ranges. Some may join multiple tables. Some may involve different kinds of databases.
Read replicas increase capacity, but they do not automatically give you control over workload shape.
DungBeetle gives control.
It can limit concurrency. It can separate heavy jobs from light jobs. It can isolate reporting from app logic. It can let multiple apps use the same reporting mechanism. It can reduce repeated pressure on source databases.
This is the deeper point.
The goal was not only to make queries faster.
The goal was to make query execution predictable.
Why Not Build This Inside Every App?
In a large organization, apps may be written in different languages and frameworks.
Data may live in PostgreSQL, MariaDB, ClickHouse, or other systems.
A single report may need data from more than one database.
If every app builds its own reporting queue, every team has to solve the same problems again:
How to queue jobs. How to limit concurrency. How to retry failed jobs. How to expose status. How to store results. How to let users fetch results. How to separate heavy and light workloads. How to avoid overloading source databases.
That creates duplicated complexity.
DungBeetle solves this by becoming a shared reporting middleware.
Applications do not need to know the internals of every database. They only need to create a job and read the result.
This is a classic platform engineering move:
Take a repeated pain point across multiple apps and turn it into a shared internal system.
A shared middleware keeps reporting logic separate from app logic and source databases.
The Senior Engineering Lesson
The most important lesson is not "use PostgreSQL for everything."
That would be the wrong takeaway.
The lesson is:
Choose the system based on the workload, not based on generic best practices.
Generic advice says millions of tables are bad.
But Zerodha's workload had unusual properties:
The data was tabular. The results were temporary. The source queries were expensive. The users needed filtering and sorting. The main databases needed protection. The results database could be disposable. The system could be wiped daily.
Under those constraints, PostgreSQL as a temporary result cache becomes reasonable.
Not because PostgreSQL is magic.
But because PostgreSQL matched the shape of the result data better than a key-value cache did.
That is what senior engineers do.
They do not blindly apply rules. They understand why the rule exists. Then they decide whether the workload is an exception.
Clever Hack Or Dangerous Hack?
This design is a hack.
Even Kailash Nadh's slide frames it with the line that the boundary between a clever software hack and outrageous abuse is thin.
But not all hacks are equal.
A dangerous hack hides risk inside the core system. A clever hack isolates risk away from the core system.
DungBeetle's Postgres result-table approach is safer because the weird part is isolated.
The main databases remain the source of truth. The reporting result database is separate. The result tables are temporary. The system has a daily reset mechanism. The app no longer hammers the source database directly.
This is why the design is defensible.
The weirdness is not allowed to leak everywhere.
It is wrapped inside a middleware with a clear boundary.
How To Explain This In One Line
Zerodha did not create 7 million PostgreSQL tables because they misunderstood databases.
They created millions of short-lived result tables in a separate PostgreSQL database so user reports could be served without repeatedly hitting massive source databases.
That is the whole idea.
Not Postgres abuse for fun.
Workload isolation.
Final Takeaway
The Zerodha DungBeetle story is interesting because it goes against common database advice but still follows strong engineering principles.
It separates heavy reporting from user-facing apps. It controls database concurrency. It avoids repeated pressure on large source databases. It uses PostgreSQL because report results are naturally tabular. It treats the results database as disposable scratch space. It keeps the unusual part isolated from the main production data model.
That is why this story is worth studying.
Not because everyone should create millions of tables.
But because it shows how production engineering often works:
Understand the workload deeply. Control the blast radius. Use boring tools creatively. And only break the rules when you know exactly which rule you are breaking.
Sources
- Kailash Nadh, IndiaFOSS 2024: "7+ million Postgres tables ft. DungBeetle"
- Kailash Nadh, "Working with PostgreSQL"
- Zerodha FOSS Stack page
