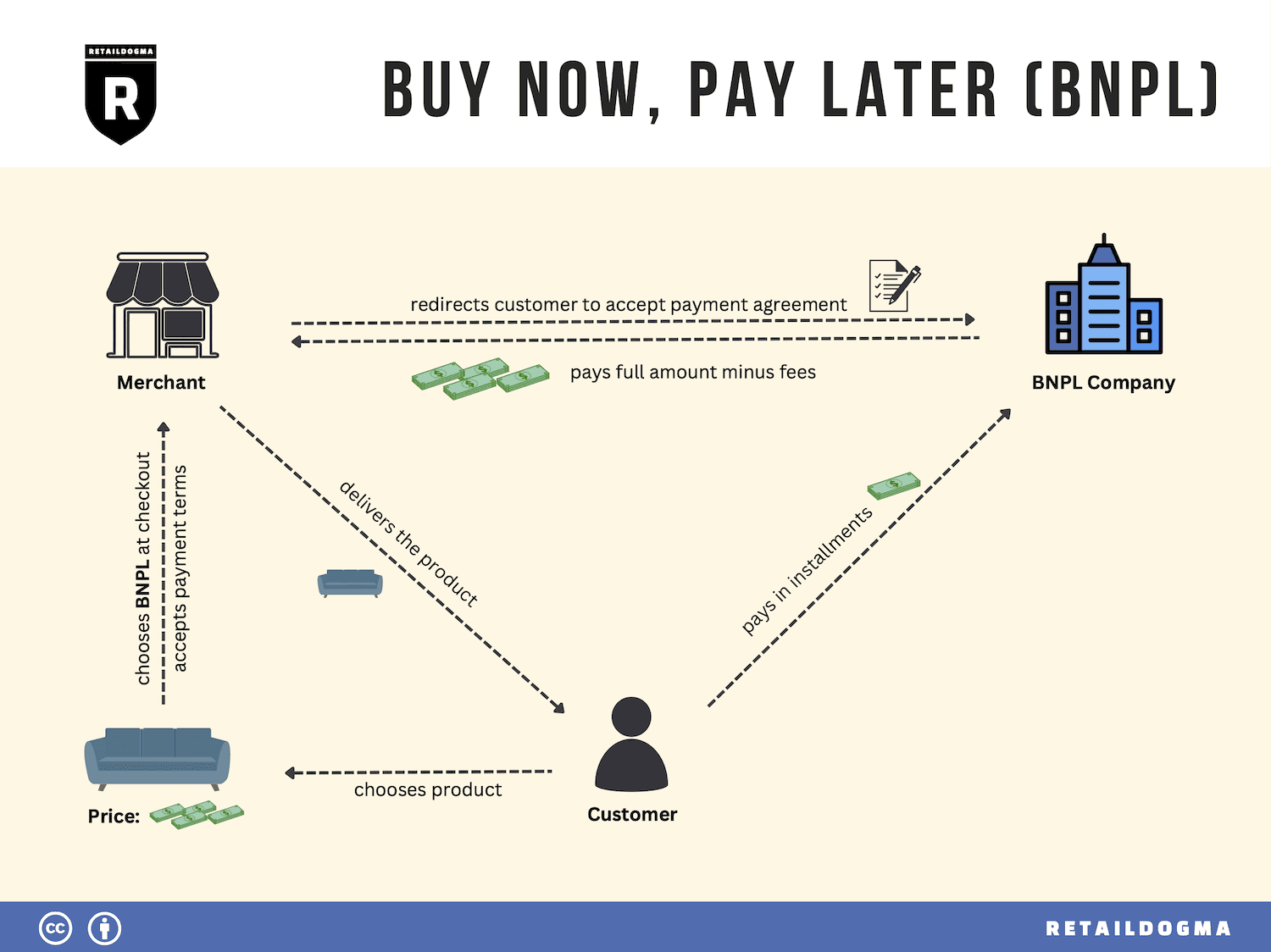
The Hook
Open a BNPL app, type a few details, tap continue, and within seconds you see a credit limit.
To most users, that feels impossible.
How can a lender decide so fast without asking for salary slips, months of bank statements, physical paperwork, or long manual verification calls?
The answer is that modern BNPL is not designed like traditional underwriting. It is designed like a low-latency distributed system.
In India, that design becomes even more powerful because the lending stack can combine digital identity rails, bureau access, device intelligence, and consent-based financial data sharing. The result is a backend that can collect signals from multiple systems at once, score risk quickly, and return a decision before the user drops off.
This is what people mean when they talk about a financial data highway.
What Instant Approval Actually Means
Instant approval does not mean every part of lending is complete in five seconds.
It usually means the system can do the following inside one short request window:
- capture the application
- verify basic identity and eligibility signals
- fetch risk data from multiple sources
- combine those signals into a consistent feature set
- calculate a risk score
- apply lender policy
- return an approve, reject, or manual review outcome
The speed comes from two things:
- better data availability
- parallel system design
Without those two, the flow becomes slow very quickly.
Why India Is a Good Environment for This Architecture
BNPL systems work best when the backend can trust structured digital signals instead of paper documents.
India is interesting because the broader financial and digital ecosystem makes this more realistic than in many markets. A lender can often build around:
- digital identity-linked onboarding
- soft bureau access
- consent-driven financial data sharing
- mobile-native user behavior signals
- bank-linked verification and repayment rails
The most important design shift is this: instead of asking the user to upload proof and waiting for humans or OCR pipelines to interpret it, the lender tries to fetch machine-readable data through consented APIs and standardized rails.
That dramatically changes system design.
The Old Lending Flow vs the New BNPL Flow
Old flow. The older underwriting mindset is document-first:
- upload documents
- wait for parsing
- wait for manual review
- call the customer
- re-check details
- decide later
That flow is slow because every step depends on the previous one.
New flow. The BNPL mindset is signal-first:
- capture a small amount of user input
- fan out to many systems in parallel
- build a risk profile in real time
- make a bounded decision fast
That is why these systems feel instant. They are not skipping underwriting. They are compressing it into a tightly engineered backend workflow.
The Core Architecture Pattern
At a high level, most instant-approval BNPL systems follow the same architecture:
- the app sends a small application payload
- the decision engine validates it
- the backend launches multiple risk checks in parallel
- each risk service returns one part of the picture
- the orchestration layer combines those parts into one feature vector
- a scoring model estimates risk
- a rules engine applies business policy
- the system stores the decision and trace
- the app receives the result
This is a classic fan-out and fan-in system: fan-out to gather signals, fan-in to produce one credit decision.
The Main Inputs Behind a Fast BNPL Decision
A lender rarely trusts one signal alone. The decision usually comes from a combination of small, fast signals.
1. Credit bureau pull
The backend asks for a quick bureau signal, often as a soft pull.
This can provide score band, repayment history summary, thin-file detection, and prior credit exposure hints.
The bureau check is useful even when the user has limited formal credit history, because it helps the system decide whether it can trust the rest of the profile.
2. Consent-based financial data fetch
This is where India's architecture becomes especially interesting.
Instead of making the user upload a PDF bank statement, the lender can request structured financial data through a consent-driven flow. In a real setup, that allows the backend to extract signals like monthly income regularity, balance trend, salary credit consistency, bounce count, and account cashflow quality.
This is important because documents are slow, messy, and easy to mishandle. Structured financial data is faster to consume, easier to model, and much easier to plug into automated underwriting.
3. Device and behavior intelligence
Modern BNPL systems look beyond declared identity.
They also inspect device fingerprint, device reuse across applications, typing cadence, form completion speed, unusual submission behavior, and duplicate patterns.
These signals are useful because fraud often appears in behavior before it appears in traditional financial data.
4. Fraud and dedupe systems
A fast credit system must protect itself from repeated applications, synthetic identities, bot-assisted submissions, shared-device abuse, and identity farming.
That is why fraud and dedupe checks usually run in the same synchronous decision path. A lender would rather slow down to manual review than auto approve a suspicious case.
Why Parallelism Is the Real Secret
This is the most important technical idea in the whole system.
Imagine four checks: bureau takes 200 ms, bank-data fetch takes 250 ms, fraud takes 120 ms, behavior analysis takes 40 ms.
If the backend runs them one by one, total time is roughly the sum.
If the backend runs them all together, total time is closer to the slowest one, plus a little orchestration overhead.
That is the real reason approval feels instant.
The backend is not waiting in a line. It is collecting evidence in parallel.
What the Orchestrator Actually Does
At the center of the design sits an orchestration service.
Its job is not to make the risk decision by itself. Its job is to coordinate the decision.
A good orchestrator usually validates the incoming payload, creates a trace id, checks idempotency so retries do not create duplicate applications, launches parallel provider calls with timeouts, collects raw outputs, builds a normalized feature set, calls the scoring layer, calls the rules layer, writes the final decision and audit trail, and returns the response.
This separation matters: providers fetch signals, feature assembly standardizes signals, models estimate risk, rules express business policy, and storage preserves the trail.
The Feature Layer: Where Raw Data Becomes Underwriting Logic
Raw provider payloads are not directly useful for lending decisions.
The backend first translates them into features such as income stability score, current balance trend, recent bounce count, bureau score band, thin-file flag, device reuse count, typing anomaly flag, unusually fast form submission flag, and requested amount versus income ratio.
This feature layer is extremely important because it creates consistency. Different providers may return very different payloads, but the scoring model and rules engine need a predictable input shape.
That feature layer is what turns a pile of API responses into an underwriting system.
Scoring Engine vs Rules Engine
Many people think lending decisions come from one model. In practice, strong systems split the problem into two parts.
Scoring engine. It answers: how risky does this applicant look based on the available signals? It produces a score, a probability-like risk estimate, and a component breakdown.
Rules engine. It answers: given this risk estimate and these hard conditions, what should the business do? Examples: if fraud is high, reject; if a critical dependency timed out, send to manual review; if the file is thin, be conservative; if the score is strong and fraud is clean, approve; if the score is borderline, route to review.
This split is powerful because the score estimates risk and the rules express lender appetite and compliance policy. That makes the system easier to tune than a single opaque decision block.
Why Manual Review Still Exists
Instant approval systems are not fully automatic in every case.
They usually reserve manual review for edge cases such as critical provider timeout, thin-file applicants, inconsistent identity signals, incomplete consent-based data, or borderline score with unusual behavior.
This is not a failure of the system. It is a safety valve.
Good lending architecture is not about approving everything quickly. It is about approving the right users quickly while containing downside risk.
Why the System Stores More Than Just Approved or Rejected
A mature BNPL backend stores the full decision trail, not just the final label.
That usually includes application record, provider snapshots, score breakdown, rule hits, audit events, and timestamps and latencies.
Why? Because lending systems need auditability, replayability, debugging, compliance support, and model improvement data.
If a lender cannot explain why a user was approved, rejected, or sent to review, the system is operationally weak no matter how fast it is.
Why Human-Readable Logging Matters
When teams build instant-credit systems, speed of debugging matters almost as much as speed of approval.
Good teams log key events like request started, provider call started and finished, branch latency, score computed, rule triggered, and decision persisted.
This is how engineers answer practical questions: why did latency spike today, which dependency is timing out, why did manual review jump, why did one cohort get rejected more often.
In a real lending company, those answers are needed daily.
What Makes the Architecture Feel Unique in India
The standout characteristic is not only that data exists. It is that data can be accessed through cleaner digital rails with user consent, allowing the underwriting engine to replace document handling with structured feature extraction.
That changes the economics of decisioning: less manual paperwork, lower friction, faster conversion, better retry handling, and cleaner signals for automated scoring.
In many countries, lenders still spend too much time converting messy documents into usable inputs. A system designed around consented financial data can skip a large part of that pain.
The Real Tradeoff Behind Instant Approval
Fast lending is not just a product challenge. It is a risk tradeoff.
Every fast BNPL backend is balancing conversion, fraud control, credit loss risk, and system latency at once.
Push too hard on conversion and the lender takes bad risk. Push too hard on strictness and good users get rejected or delayed. Push too hard on too many synchronous dependencies and latency rises.
So the architecture is always trying to find the best compromise: enough data to be safe, fast enough to keep the user engaged, simple enough to operate reliably.
A Good One-Sentence Explanation
Modern BNPL in India works fast because the lender collects multiple financial and behavioral signals in parallel through digital rails, converts them into machine-readable features, scores the user instantly, applies strict fraud and policy checks, and returns a credit decision in seconds.
Final Takeaway
The secret behind instant BNPL approval is not one company and not one algorithm. It is architecture.
The lender turns underwriting from a slow document-review workflow into a fast data-orchestration workflow. Bureau data, consent-based financial data, fraud signals, device telemetry, scoring, and rule evaluation all work together inside one short backend path.
That is why a user can go from form submission to credit decision so quickly.
The system is not doing less underwriting. It is doing underwriting in a way that is engineered for speed.
